

i-AI
Our approach to a company's internal AI solution (i-AI)
An on-premise AI solution refers to the implementation and operation of AI systems on a company's own hardware and infrastructure, rather than using cloud-based services. This offers specific advantages in terms of data protection, security, and control over sensitive company data.
An AI solution can consist of only rudimentary elements from standardized modules, which are ideally discussed and developed in a workshop. Here, we provide an overview of most of the relevant topics.
A workshop should not only involve IT experts, but also key employees who will be working with this AI in the future and who will bring the topic to the departments.
_________________________________________________________________________________________________________________
Table of Contents
How AI Works
This is i-AI
Structure for our company's internal AI solution: i-AI
Data structure for the i-AI system
SLM or LLM
ETL process (Extract, Transform, and Load)
Technical infrastructure
AI Hardware
- Technical infrastructure for an internal AI
- Internal AI factory
- Security for an internal AI system
- AI hardware for AI software development
- Hardware for the AI factory
i-AI software modules in operation
- Chatbot as a switchboard
- Agentic AI
- AI-supported workflow automation
- AI-supported cybersecurity
- Internal AI research, leveraging company knowledge
- Combining internal AI research with generative AI systems, leveraging global knowledge
__________________________________________________________________________________________________
This is how AI works
Artificial intelligence (AI) works essentially by allowing computers to learn from huge amounts of data , recognize patterns, and use this information to solve tasks or make predictions, without each step being explicitly programmed into them.
Here's a simple explanation of how it works:
1. Data acquisition (input)
The process begins with a large amount of data, for example images. This data is fed into the AI.
2. Pattern Recognition and Learning
This is the core of AI and is often referred to as machine learning :
- Algorithms: The AI uses special algorithms (computational instructions) to process the data and identify statistical patterns.
- Training: During this "training," the system learns which characteristics distinguish a cat from a dog. It is iteratively adjusted to make increasingly accurate predictions.
3. Decision-making (Output)
Once the model is trained, it can make decisions or predictions based on new, previously unknown data.
4. Continuous Improvement
Advanced AI systems can continuously learn and improve their accuracy with each new experience and more data.
Key concepts
- Machine learning: The main mechanism by which AI systems learn and improve.
- Neural networks (deep learning): An advanced form of machine learning that is structured like a simplified human brain and is particularly well suited for complex tasks such as image and speech recognition.
- Weak vs. Strong AI: Almost all current AI systems are "weak" AIs, capable of solving only very specific tasks (e.g., playing chess, translating language). "Strong" AI, capable of mimicking human intelligence in all its facets, is still a thing of the future. Initial results include the capabilities of modern AI systems such as GPT & Co.
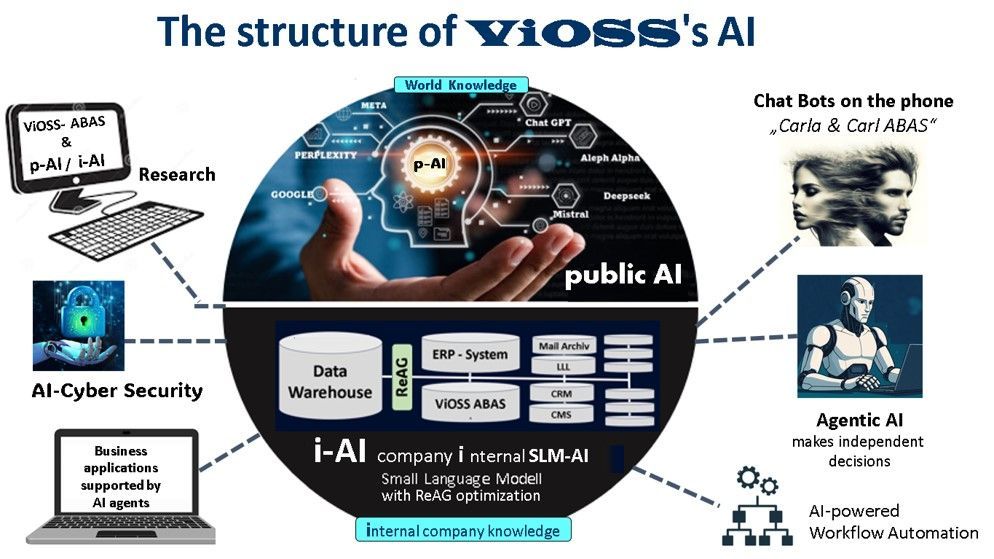
Structure for our company's internal AI solution:
i-AI
An optimal structure for an in-house AI solution is based on a scalable, modular architecture that integrates various key components, from the data foundation to governance. This architecture offers flexibility for integrating new data sources and AI models while ensuring security and compliance standards.
This is i-AI
In-house AI refers to an internally operated AI platform that runs entirely within your own IT infrastructure – independent of external cloud providers such as OpenAI, Google, or Microsoft. It is usually based on so-called Large Language Models (LLMs) , which are specifically adapted for use within the company.
If you want to implement AI in your company, an in-house solution is often the safest and most sustainable option: Your employees gain secure, direct access to generative AI – with clear access control , data sovereignty , integration with internal systems, and governance that you define yourself. This allows you to leverage the full potential of AI – without data privacy risks or dependencies on third parties.
The core components of an optimal internal AI solution
The structure can be divided into several interconnected layers or building blocks:
1. Data infrastructure and management:
This is the foundation of every AI solution.
- Data sources: Integration of heterogeneous internal and, if applicable, external data sources.
- Data integration & processing: Mechanisms to collect, clean, transform and structure data in (near) real time.
- Data storage: A robust, scalable database or data lake solution designed for large amounts of data.
- Data governance: Guidelines and processes for data quality, security, data protection (compliance, e.g. GDPR) and access control.
2. AI Platform (AI Hub):
The central environment for the development, training, and operation of AI models.
- Development environment: Tools and frameworks for data scientists and developers.
- MLOps (Machine Learning Operations): Processes and tools for the entire life cycle of an AI model, from development and deployment to monitoring and re-optimization.
- Model Registry: A central repository for managing and versioning trained models.
- Computing infrastructure: Scalable and high-performance hardware.
3. AI applications and integration:
The layer in which AI models are embedded in business processes.
- Interfaces (APIs): Standardized APIs enable the seamless integration of AI functionalities into existing enterprise software (e.g. CRM, ERP, internal tools).
- Application layer: Pre-built or custom AI applications (e.g., chatbots, analytics tools, process automation).
- User interfaces: Intuitive dashboards or interfaces for end users.
4. Governance and Operations:
Overarching structures that ensure the responsible and efficient use of AI.
- AI strategy: Clear definition of goals and prioritization of use cases.
- Organizational integration: Definition of responsibilities and development of internal AI expertise (e.g., a "Center of Excellence").
- Compliance & Ethics: Ensuring that all AI activities comply with relevant laws (e.g. EU AI Act) and internal ethical guidelines.
- Monitoring & Maintenance: Ongoing monitoring of model performance in productive use and adjustment as needed.
Best practices for implementation
- Modularity: Using a modular design to ensure flexibility and not be tied to specific tools or vendors.
- Scalability: The architecture grows with increasing data volumes and a growing number of AI use cases.
- Standardization: Clear technological standards and processes (especially MLOps) are crucial to managing complexity.
- Security first: Security measures will be integrated into every layer from the outset, especially when handling sensitive company data.
Structure of the data for the i-AI system
For an in-house AI system, various data must be taken into account, which can be divided into the following main categories:
data types , data quality , and legal and ethical aspects .
1. Types of data to be considered
The type of data depends heavily on the specific use case of the AI system. Generally, a distinction is made between:
- Structured data:
- Customer data (CRM data)
- Financial data (accounting, transactions)
- Production data (sensor data, quality control)
- Logistics data (inventory management, route planning)
- HR data (employee master data, performance reviews)
- Unstructured data:
- Text documents (emails, reports, contracts)
- Images and videos (quality control, security)
- Audio recordings (speech recognition)
- Machine data (log files)
- Internal and external data:
- Internal data originates from the company's own systems.
- External data can come from public sources (e.g., weather data, market data) or from data providers to enrich the model.
2. Data quality and preparation
The quality of the data is crucial for the performance of the AI system. The following must be considered:
- Completeness: Is all relevant information present?
- Accuracy: Is the data error-free?
- Consistency: Is the data consistent across different sources?
- Timeliness: Is the data regularly maintained and updated?
- Data preparation (annotation): For many AI models, data needs to be labeled or annotated manually or automatically, which is time-consuming and requires expertise.
3. Legal and ethical aspects
Compliance with regulations is a must, especially when handling sensitive data:
- Data protection (GDPR): The processing of personal data is subject to strict rules. A legal basis (e.g., consent, legitimate interest) must exist for the processing.
- Access rights: Access control must ensure that only authorized persons and systems can access the data.
- Transparency and documentation: Transparency and documentation obligations must be observed, especially for high-risk AI systems in accordance with the EU AI Regulation (AI Act).
- Data ethics: The company should develop internal guidelines that regulate the responsible handling of data and the fair use of AI.
- Copyright: When using external data or training with publicly accessible content, copyright laws must be observed.
In summary, the selection, preparation, and legally compliant use of data are essential steps for the successful and responsible use of an in-house AI system.
______________________________________________________________________________________________________________
SLM or LLM
The main difference between Small Language Models (SLM) and Large Language Models (LLM) lies in their size (number of parameters), the resources required , and their capabilities .
SLM vs. LLM: The differences
Feature
Small Language Model (SLM)
Large Language Model (LLM)
Number of parameters
Fewer parameters (millions to a few billion)
Many parameters (hundreds of billions to trillions)
Training
Faster training, lower energy consumption
Lengthy and expensive, high energy consumption
Resource requirements
Small amount
High (requires powerful cloud resources)
Provision
Ideal for local devices ("edge devices"), offline capable
Usually requires cloud infrastructure
Speed
Faster processing and response times
Slower due to complexity
Skills
Specialized in specific, narrowly defined tasks; lower generalizability
Broad general knowledge; good for complex tasks and deep contextual understanding.
Adjustment
Easier and more cost-effective to fine-tune for specific applications.
More complex and expensive to adapt.
In summary:
- LLMs are general-purpose models designed for a wide range of complex tasks. They offer comprehensive capabilities but require significant computational resources.
- SLMs are smaller, more efficient models optimized for specific, specialized tasks. They are faster, more cost-effective to operate, and can be used on devices with limited resources (e.g., smartphones, embedded systems).
The choice between an SLM and an LLM depends on the specific use case, the available resources, and the requirements for speed and data sovereignty.
Security for a company's internal AI system
A company's internal AI system must be extremely secure against hacker attacks. How can this security be optimally achieved?
To optimally protect an in-house AI system from hacker attacks, a
holistic security approach is required, encompassing both general IT security measures and specific precautions for AI threats. Security must be guaranteed throughout the system's entire lifecycle, from development to operation.
General IT security measures
These fundamental measures form the basis for the security of the AI system:
- Network segmentation : Isolate the AI system from the rest of the company network and especially from the internet to minimize the attack surface.
- Access controls : Implement strict access restrictions and the principle of least privilege. Use multi-factor authentication (MFA) wherever possible .
- Encryption : Secure sensitive data both during transmission (data in transit) and at rest (data at rest) through strong encryption.
- Regular updates and patch management : Keep your entire software infrastructure, including operating systems, libraries, and AI frameworks, up to date to close known vulnerabilities.
- Employee training : Raise employee awareness of cyber threats and safe behaviors, as human error is often an entry point for attacks.
- Continuous monitoring : Implement systems for real-time detection of anomalies and unexpected behavior in the network and within the AI system.
AI-specific security measures
AI systems bring with them their own unique vulnerabilities that require additional protective measures:
- Validation and cleansing of input and output data : Filter and validate all data fed into the AI model to prevent so-called "jailbreak" attempts or "injection" attacks. Also filter the outputs to prevent the system from revealing harmful or sensitive information.
- Robustness tests : Specifically test the AI model for its resilience to manipulated input data (adversarial examples) and other manipulation attempts.
- Human-in-the-Loop oversight : Especially in high-risk AI systems, human oversight should be implemented to quickly detect and correct incorrect decisions or abuse.
- Explainable AI (XAI) : Make the decisions of the AI system comprehensible in order to better analyze and correct unexpected or faulty behavior.
- Securing the supply chain : Check third-party components and open-source libraries used in the AI infrastructure for security vulnerabilities.
- Data Protection Impact Assessment (DPIA) : Conduct a DPIA in accordance with the GDPR to identify and minimize data protection risks, especially when handling personal training data.
By combining these technical and organizational measures, the security of the internal AI system can be optimally achieved. Furthermore, it is recommended to consult the guidelines of the Federal Office for Information Security (BSI) and, if necessary, to take out cyber insurance.
_____________________________________________________________________________
ETL process
The complex ETL process stands for Extract , Transform and Load.
It is a prerequisite for acquiring, cleaning, and structuring internal company data as the basis for i-AI (internal company AI solutions). The graphic illustrates how the ETL process works:
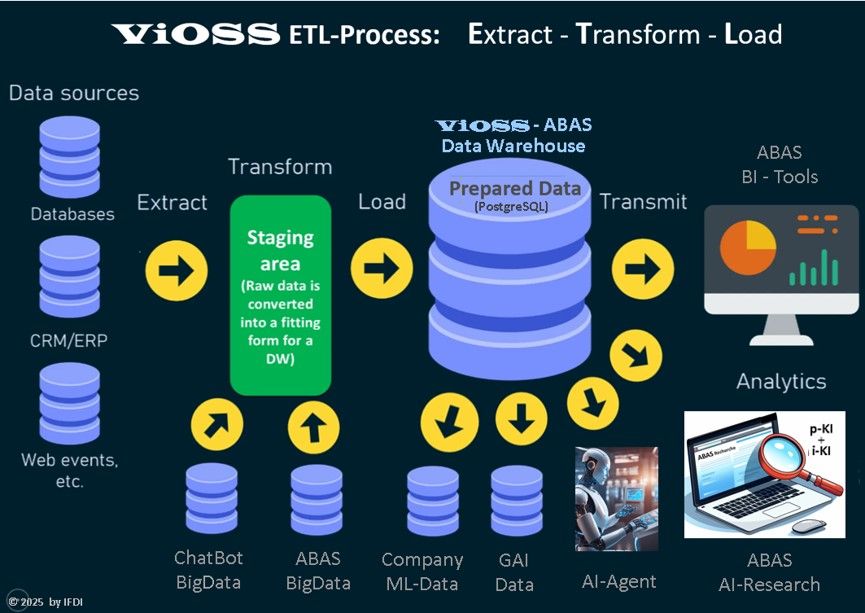
The ETL process
In connection with the development of in-house AI, the following specific and extended tasks arise for the ETL process (Extract, Transform, Load):
Extract
- Identifying and aggregating heterogeneous data sources: AI models often require data from a variety of internal (ERP, CRM, databases, documents) and potentially external sources. The task is to identify these diverse data sources and efficiently extract the relevant data, regardless of its format (structured, unstructured).
- Ensuring data origin and quality: It must be ensured that the extracted data is trustworthy and that its origin is clearly traceable, which is crucial for quality assurance of the subsequent AI models.
Transform
This is the most critical phase for AI development:
- Data cleansing: Raw data often contains errors, inconsistencies, or missing values. The ETL process must implement cleansing algorithms to ensure data accuracy and consistency (e.g., removing duplicates, correcting errors, imputing missing values).
- Data enrichment: To improve the predictive power of AI, data is enriched by adding relevant information, for example by integrating additional internal or external datasets.
- Feature Engineering: This involves creating new, relevant features from existing data that are useful for the specific AI or machine learning model. This often requires domain-specific knowledge.
- Data formatting and structuring: Data must be converted into a format suitable for training AI models (e.g., standardization, normalization, categorical variable coding).
- Data annotation and labeling: For many AI applications, especially in supervised learning, data must be labeled or annotated (e.g., images with object names, texts with sentiment analyses). The ETL process must support and quality control the integration of these (often manual or semi-automated) annotation steps.
- Anonymization/Pseudonymization: To comply with data protection regulations (such as GDPR), sensitive company and personal data must be anonymized or pseudonymized during the transformation before being used for AI training.
Load
- Loading into AI-specific storage: The transformed data is not only loaded into a classic data warehouse, but often into special data platforms such as data lakes or feature stores that are optimized for machine learning workloads.
- Data versioning: Managing different versions of training data is crucial for the traceability and reproducibility of AI experiments. The ETL process must support this versioning.
- Provision for continuous training: For learning AI systems, the ETL process must be able to continuously provide new, prepared data for the regular retraining of the models.
In summary, the ETL process plays a central role in the data pipeline for i-AI by transforming raw data into high-quality, modelable datasets that are crucial for the success of in-house AI projects.
___________________________________________________________________________
Technical infrastructure
For an on-premise AI infrastructure, a combination of high-performance hardware, specialized software, and a robust network architecture is required.
Hardware components
The hardware forms the backbone for the training and operation of AI models and must be designed for high computing loads.
- Processors (CPUs, GPUs, TPUs):
- CPUs (Central Processing Units) are necessary for general tasks and orchestration.
- However, GPUs (Graphics Processing Units) are crucial because they are optimized for the parallel processing of matrix and vector calculations that arise during AI training.
- More specialized hardware such as TPUs (Tensor Processing Units) or FPGAs can also be used depending on the application, but are less common in general on-premise setups.
- Memory: Much faster memory (RAM and VRAM) is required, often in the range of 32 GB, 64 GB or more, depending on the complexity of the models and data volumes.
- Storage: A combination of fast, non-volatile storage such as SSDs (Solid State Drives) for fast data access and larger HDDs (Hard Disk Drives) for archiving large amounts of data is required.
- Network: A high-performance network infrastructure is necessary to quickly transfer large datasets between storage, computing units, and the developers' workstations.
Software-Stack
The software layer enables the development, training, and deployment of AI applications.
- Operating system and virtualization: A stable operating system (often Linux-based) and possibly virtualization or containerization platforms (e.g. Docker, Kubernetes) for efficient resource utilization.
- AI frameworks and libraries: Tools like TensorFlow and PyTorch are standard libraries for machine learning and deep learning.
- Programming languages: Python is the most widely used language in the AI field, often in conjunction with data analysis libraries such as Pandas or NumPy.
- Data processing platforms: Distributed computing platforms such as Apache Spark can be useful for processing huge amounts of data.
- Management and orchestration tools: Software for managing computing loads, monitoring infrastructure, and automating workflows (MLOps).
Data management
AI thrives on data, therefore a robust data foundation is crucial.
- Data pipelines: Processes for collecting, integrating, cleaning, and normalizing data.
- Databases and data lakes: Secure storage systems for large amounts of high-quality data needed for training.
- Data security and privacy: Especially with internal company data, high standards for security and compliance are required, which is often easier to guarantee with an on-premise solution than in the cloud.
_____________________________________________________________________________________________________

AI-Hardware
In the field of AI, we plan to include two "hardware products" in our sales portfolio as an MSP (Managed Service Provider) partner, in addition to consulting and software, in order to offer our customers a full service.
AI hardware for AI software development
We will use this new AI hardware from NVIDIA for our internal AI development and, with this know-how, distribute this product to our customers as an MSP (Managed Service Provider).
NVIDIA Project Digits is marketed as an AI supercomputer for developers. Despite its extremely compact dimensions, the device promises immense performance, for which NVIDIA relies on a newly developed GB10 "superchip" created in collaboration with MediaTek.
This card boasts 20 high-performance cores, including ten ARM Cortex-X925 and ten Cortex-A725. The integrated graphics chip is based on the Blackwell architecture, already familiar from the GeForce RTX 5000 series. Nvidia provides little concrete information regarding the specifications or performance of this GPU, promising only 1 petaflop of performance (one petaflop equals one quadrillion (10¹⁵) floating-point operations per second). However, this refers to FP4 performance and is therefore not comparable to specifications for conventional graphics cards, which typically quote FP32 performance. This FP4 performance is intended to be particularly useful for AI applications.
One advantage of Project Digits over systems with dedicated desktop graphics cards is that the graphics chip has access to more memory, as Nvidia has included 128 GB of DDR5X RAM. With a 4 TB SSD, Wi-Fi, Bluetooth, and USB ports, Project Digits is well-suited for desktop use. While Project Digits is primarily intended for developers, this GB10 chip could be a first step towards Nvidia's desktop processors.
Developers can use common tools such as PyTorch, Jupyter and Ollama to create prototypes, fine-tune and inferencing on DGX Spark, and seamlessly implement it in the DGX Cloud or any accelerated data center or cloud infrastructure.
The advantages: The independence of AI development from data centers greatly accelerates AI development, as all necessary tests can be carried out locally. And that reduces costs.
This is the Link to a detailed description.
AI Desktop for Development:

___________________________________________________________________________________________________________
Hardware for the "AI factory"
Building an in-house "AI factory" requires a robust hardware infrastructure combined with a comprehensive security concept. Here are the essential hardware components and security measures:
Hardware components for the AI factory
The hardware must be designed for computationally intensive tasks such as AI training, fine-tuning, and inference (application).
- GPUs (Graphics Processing Units): This is the most important component, as GPUs are optimized for deep learning tasks through parallel processing.
- Recommendation: High-end GPUs such as the NVIDIA A100, H100, or RTX 6000 Ada series are recommended for demanding workloads. For smaller installations or specific tasks, models like the NVIDIA RTX 3080/3090 may also be sufficient.
- CPUs (Central Processing Units): High-quality multi-core processors (e.g., Intel Xeon or AMD EPYC) are required to coordinate overall system performance and data processing.
- RAM/VRAM:
- System RAM: At least 128 GB for server setups, for very large models often 64 GB or more per workstation.
- VRAM (Video RAM): Crucial for the size of the models that can be loaded and trained. GPUs with large VRAM (e.g., 40 GB or more) are advantageous here.
- Storage:
- NVMe SSDs: High capacity and speed are crucial for fast data access and avoiding waiting times at the processing units. Depending on the data size, they can require several terabytes of storage space.
- Data storage systems: Scalable storage solutions (e.g., HPE GreenLake for File Storage) for managing massive amounts of data.
- Network: High-speed connectivity (e.g., 400GbE or higher) is required to efficiently move data between the GPU servers and storage systems.
- Power supply and cooling: High-performance hardware requires a suitable power supply and cooling systems, possibly even liquid cooling, to ensure stable operation.
- Racks and enclosures: Server cabinets with sufficient space and efficient air circulation.
Security concept and measures (hardware-related)
The security of the internal AI factory requires a "security-by-design" approach that considers the entire infrastructure and lifecycle of the AI.
- Physical security: Restrict physical access to the servers and racks to authorized personnel.
- Network segmentation: Isolate the AI infrastructure from the rest of the corporate network with dedicated hardware firewalls (next-generation firewalls) and secure VPN connections.
- Hardware Security Modules (HSMs): Use HSMs to securely store and manage cryptographic keys for data and model encryption. This protects against unauthorized access to sensitive data and stolen models.
- Hardware-based security features: Leverage platforms that offer integrated hardware security features (e.g., Intel vPro or specific security chips) to reduce attack surfaces.
- Encryption: Implement end-to-end encryption of data at rest (e.g., on SSDs) and data in transit.
- Access controls (Identity and Access Management, IAM): Enforce strict role-based access controls (RBAC) and the principle of least privilege at the hardware and software levels to ensure that only authorized users can access specific resources.
- Monitoring and auditing: Implement continuous monitoring systems to detect unusual behavior or potential security threats in real time and maintain audit logs.
- Supply Chain Security: Ensure that hardware is sourced from trusted suppliers and that the entire lifecycle of the components is traceable to prevent tampering.
In this context, we will cooperate with the supplier HPE.
HPE stands for Hewlett Packard Enterprise Company, a large American information technology company. It emerged from the split of the original Hewlett-Packard Company in 2015.
Business areas of Hewlett Packard Enterprise (HPE)
HPE focuses on solutions and services for business customers and large enterprises in the following areas:
- Server, Storage and Networking: Provision of hardware and solutions for data centers, data storage (e.g. HPE Alletra, HPE MSA Storage) and network infrastructures (via subsidiary Aruba Networks).
- High Performance Computing & AI: Development of supercomputers (after the acquisition of Cray) and AI applications for intensive calculations and data analysis.
- Hybrid Cloud & Edge-to-Cloud: Provision of cloud-native data infrastructure solutions that enable seamless management of data and workloads across on-premises data centers, edge locations, and public clouds, including via the HPE GreenLake platform.
HPE (Hewlett Packard Enterprise) and NVIDIA maintain an intensive strategic partnership , which focuses primarily on the development and delivery of solutions for artificial intelligence (AI) and supercomputing .
The collaboration covers the following core areas:
- AI Computing Solutions (“NVIDIA AI Computing by HPE”) :
HPE and NVIDIA have jointly developed integrated, pre-configured solutions designed to accelerate the adoption of AI in businesses. This includes “HPE Private Cloud AI,” which is based on validated NVIDIA designs and makes it easier for companies to run generative AI applications in their own controlled private cloud infrastructure.
- Hardware integration : The partnership includes the integration of NVIDIA's high-performance GPUs (such as the Blackwell and RTX PRO 6000 Server Edition GPUs) and AI software into HPE systems, especially the HPE ProLiant Compute Servers and HPE Cray Supercomputing systems.
- Supercomputer projects : A prominent example of cooperation in the field of supercomputing is the planned construction of a new supercomputer at the Leibniz Computing Centre (LRZ) in Germany ("Blue Lion").
- Unified data layer : One focus of the development is also on a unified data layer that should make company data usable and accessible for AI applications.
- Simplified implementation : The goal is to reduce the complexity of AI implementation so that companies can use AI models faster (in some cases, deployment in a few seconds and with a few clicks is the aim) and more easily.
In summary, the partnership aims to combine HPE's enterprise expertise with NVIDIA's leading AI technology to drive the industrial revolution of generative AI.
"NVIDIA AI Computing by HPE"
An on-premise AI solution refers to the implementation and operation of AI systems on a company's own hardware and infrastructure, rather than using cloud-based services. This offers specific advantages in terms of data protection, security, and control over sensitive company data.
Follow this Link.
