

i-KI
Unser Lösungsansatz für eine firmen interne KI-Lösung (i-KI)
"Der hohe Preis des Zögerns im KI-Zeitalter"
Europa mag das Rennen um die führenden Basismodelle verloren haben. Aber das entscheidende Wettrennen findet nicht in den Forschungslaboren der USA oder China statt, sondern in den Unternehmen, die diese Modelle produktiv nutzen. Die Chancen sind enorm, die Kosten transparent, der Nutzen ist empirisch belegt, der Preis des Zögerns ist hoch.
Die entscheidende Frage lautet daher nicht mehr, ob Unternehmen generative KI einsetzen sollten, sondern:
Wie lange können sie es sich noch leisten, es nicht zu tun?
Zitat von Professor Peter Buxmann, von der Technischen Universität Darmstadt (FAZ 15.12.2025)
_________________________________________________________________________________________________________________
Eine firmeninterne (On-Premise) KI-Lösung bezeichnet die Implementierung und den Betrieb von KI-Systemen auf der eigenen Hardware und Infrastruktur eines Unternehmens, anstatt cloudbasierte Dienste zu nutzen. Dies bietet spezifische Vorteile hinsichtlich Datenschutz, Sicherheit und Kontrolle über sensible Unternehmensdaten.
Eine i-KI Lösung kann nur in rudimentären Elementen aus standardisierten Modulen bestehen, die idealerweise in einem Workshop diskutiert und erarbeitet werden. An dieser Stelle geben wir einen Überblick über die meisten in Frage kommenden Themen.
In einem Workshop sollten nicht nur IT-Experten beteiligt sein, vielmehr sollten auch wichtige Mitarbeiter eingebunden werden, die zukünftige mit dieser KI arbeiten sollen.
Inhaltsverzeichnis
- So funktioniert KI
- Das ist i-KI
- Struktur für unsere Firmen interne KI-Lösung: i-KI
- Struktur der Daten für das i- KI System
- SLM oder LLM
- KI-Hardware
- Technische Infrastruktur für eine Firmen interne KI
- Firmen interne „KI-Fabrik“
- Sicherheit für ein Firmen internes KI-System
- ETL-Prozess (Extrahieren, Transformieren und Laden)
- Das Struktur der KI vonViOSS
- Technische Infrastruktur
- KI-Hardware
- KI-Hardware für die KI-Software-Entwicklung
- Hardware für die "KI-Fabrik"
Software-Module der i-KI im operativen Betrieb
- Chat-Bot als Telefonzentrale
- Agentic KI
- KI gestützte Workflow Automatisierung
- KI-gestützte Cybersicherheit
- Firmeninterne KI-Recherchen, dem Firmenwissen
- Kombination interner KI-Recherchen mit generativen KI-Systemen, dem Weltwissen
_____________________________________________________________________________________________________
So funktioniert KI
Künstliche Intelligenz (KI) funktioniert im Kern dadurch, dass Computer aus riesigen Datenmengen lernen, Muster erkennen und auf dieser Basis Aufgaben lösen oder Vorhersagen treffen, ohne dass ihnen jeder Schritt explizit einprogrammiert wurde.
Hier ist die Funktionsweise einfach erklärt:
1. Datenaufnahme (Input)
Der Prozess beginnt mit einer großen Menge an Daten, zum Beispiel Bildern. Diese Daten werden der KI zugeführt.
2. Mustererkennung und Lernen
Dies ist das Herzstück der KI und wird oft als Maschinelles Lernen bezeichnet:
- Algorithmen: Die KI verwendet spezielle Algorithmen (Rechenanweisungen), um die Daten zu verarbeiten und statistische Muster zu identifizieren.
- Training: Während dieses "Trainings" lernt das System, welche Merkmale eine Katze von einem Hund unterscheiden. Es wird iterativ angepasst, um immer genauere Vorhersagen zu treffen.
3. Entscheidungsfindung (Output)
Sobald das Modell trainiert ist, kann es auf Basis neuer, ihm unbekannter Daten Entscheidungen treffen oder Vorhersagen machen.
4. Kontinuierliche Verbesserung
Fortgeschrittene KI-Systeme können kontinuierlich weiterlernen und ihre Genauigkeit mit jeder neuen Erfahrung und mehr Daten verbessern.
Schlüsselkonzepte
- Maschinelles Lernen (Machine Learning): Der Hauptmechanismus, durch den KI-Systeme lernen und sich verbessern.
- Neuronale Netze (Deep Learning): Eine fortschrittliche Form des maschinellen Lernens, die wie ein vereinfachtes menschliches Gehirn aufgebaut ist und besonders gut für komplexe Aufgaben wie Bild- und Spracherkennung geeignet ist.
- Schwache vs. Starke KI: Fast alle heutigen KI-Systeme sind "schwache" KIs, die nur sehr spezifische Aufgaben lösen können (z.B. Schach spielen, Sprache übersetzen). "Starke" KI, die menschliche Intelligenz in all ihren Facetten nachahmen kann, ist noch Zukunftsmusik. Erste Resultate sind die Fähigkeiten moderner KI-Systeme wie GPT & Co.
_________________________________________________________________________________________________________
Das ist i-KI
Inhouse KI bezeichnet eine intern betriebene KI-Plattform, die vollständig in Ihrer eigenen IT-Infrastruktur läuft – unabhängig von externen Cloud-Anbietern wie OpenAI, Google oder Microsoft. Sie basiert meist auf sogenannten Large Language Models (LLMs), die speziell für den Einsatz im Unternehmen angepasst werden.
Wenn Sie KI im Unternehmen einsetzen möchten, ist eine Inhouse-Lösung oft die sicherste und nachhaltigste Option: Ihre Mitarbeitenden erhalten sicheren, direkten Zugang zu generativer KI – mit klarer Zugriffskontrolle, Datenhoheit, Anbindung an interne Systeme und einer Governance, die Sie selbst bestimmen. So nutzen Sie das volle Potenzial von KI – ohne Datenschutzrisiken oder Abhängigkeiten von Dritten.
Struktur für unsere Firmen interne KI-Lösung: i-KI
Eine optimale Struktur für eine firmeninterne KI-Lösung basiert auf einer skalierbaren, modularen Architektur, die verschiedene Schlüsselkomponenten integriert, von der Datenbasis bis zur Governance. Die Architektur bietet Flexibilität für die Integration neuer Datenquellen und KI-Modelle und gleichzeitig Sicherheits- sowie Compliance-Standards gewährleistet.
Die Kernkomponenten einer optimalen internen KI-Lösung
Die Struktur lässt sich in mehrere, miteinander verbundene Schichten oder Bausteine unterteilen:
1. Daten-Infrastruktur und -Management:
Dies ist das Fundament jeder KI-Lösung.
- Datenquellen: Integration heterogener interner und ggf. externer Datenquellen.
- Datenintegration & -verarbeitung: Mechanismen, um Daten in (nahezu) Echtzeit zu sammeln, zu bereinigen, zu transformieren und zu strukturieren.
- Datenspeicherung: Eine robuste, skalierbare Datenbank- oder Data-Lake-Lösung, die für große Datenmengen ausgelegt ist.
- Daten-Governance: Richtlinien und Prozesse für Datenqualität, -sicherheit, Datenschutz (Compliance, z.B. DSGVO) und Zugriffskontrolle.
2. KI-Plattform (KI-Hub):
Die zentrale Umgebung für die Entwicklung, das Training und den Betrieb von KI-Modellen.
- Entwicklungsumgebung: Tools und Frameworks für Data Scientists und Entwickler.
- MLOps (Machine Learning Operations): Prozesse und Tools für den gesamten Lebenszyklus eines KI-Modells, von der Entwicklung über das Deployment bis hin zum Monitoring und der Re-Optimierung.
- Modell-Registry: Ein zentrales Repository zur Verwaltung und Versionierung trainierter Modelle.
- Recheninfrastruktur: Skalierbare und leistungsstarke Hardware.
3. KI-Anwendungen und Integration:
Die Schicht, in der die KI-Modelle in Geschäftsprozesse eingebettet werden.
- Schnittstellen (APIs): Standardisierte APIs ermöglichen die nahtlose Integration der KI-Funktionalitäten in bestehende Unternehmenssoftware (z.B. CRM, ERP, interne Tools).
- Anwendungsschicht: Vorgefertigte oder kundenspezifische KI-Anwendungen (z.B. Chatbots, Analyse-Tools, Automatisierung von Prozessen).
- Benutzeroberflächen: Intuitive Dashboards oder Oberflächen für Endnutzer.
4. Governance und Betrieb:
Übergreifende Strukturen, die den verantwortungsvollen und effizienten Einsatz von KI sicherstellen.
- KI-Strategie: Klare Definition von Zielen und Priorisierung von Anwendungsfällen.
- Organisatorische Einbindung: Definition von Zuständigkeiten und Aufbau interner KI-Kompetenzen (z.B. ein "Center of Excellence").
- Compliance & Ethik: Sicherstellung, dass alle KI-Aktivitäten den relevanten Gesetzen (z.B. EU AI Act) und internen ethischen Richtlinien entsprechen.
- Monitoring & Wartung: Laufende Überwachung der Modellleistung im produktiven Einsatz und Anpassung bei Bedarf.
Best Practices für die Umsetzung
- Modularität: Verwendung eines modularen Aufbaus, um Flexibilität zu gewährleisten und nicht an spezifische Tools oder Anbieter gebunden zu sein.
- Skalierbarkeit: Die Architektur wächst mit steigenden Datenmengen und einer wachsenden Anzahl von KI-Anwendungsfällen.
- Standardisierung: Klare technologische Standards und Prozesse (insbesondere MLOps) sind entscheidend, um Komplexität zu bewältigen.
- Sicherheit an erster Stelle: Sicherheitsmaßnahmen werden von Beginn an in jede Schicht integriert werden, besonders beim Umgang mit sensiblen Unternehmensdaten.
Struktur der Daten für das i- KI System
Für ein firmeninternes KI-System müssen verschiedene Daten berücksichtigt werden, die sich in folgende Hauptkategorien unterteilen lassen: Datenarten, Datenqualität sowie rechtliche und ethische Aspekte.
1. Arten der zu berücksichtigenden Daten
Die Art der Daten hängt stark vom spezifischen Anwendungsfall des KI-Systems ab. Generell unterscheidet man zwischen:
- Strukturierte Daten:
- Kundendaten (CRM-Daten)
- Finanzdaten (Buchhaltung, Transaktionen)
- Produktionsdaten (Sensordaten, Qualitätskontrolle)
- Logistikdaten (Bestandsmanagement, Routenplanung)
- HR-Daten (Mitarbeiterstammdaten, Leistungsbeurteilungen)
- Unstrukturierte Daten:
- Textdokumente (E-Mails, Berichte, Verträge)
- Bilder und Videos (Qualitätskontrolle, Sicherheit)
- Audioaufnahmen (Spracherkennung)
- Maschinendaten (Logfiles)
- Interne und externe Daten:
- Interne Daten stammen aus den eigenen Systemen des Unternehmens.
- Externe Daten können aus öffentlichen Quellen (z.B. Wetterdaten, Marktdaten) oder von Datenanbietern stammen, um das Modell zu bereichern.
2. Datenqualität und -aufbereitung
Die Qualität der Daten ist entscheidend für die Leistungsfähigkeit des KI-Systems. Zu berücksichtigen sind:
- Vollständigkeit: Sind alle relevanten Informationen vorhanden?
- Korrektheit: Sind die Daten fehlerfrei?
- Konsistenz: Sind die Daten über verschiedene Quellen hinweg einheitlich?
- Aktualität: Werden die Daten regelmäßig gepflegt und aktualisiert?
- Datenaufbereitung (Annotation): Für viele KI-Modelle müssen Daten manuell oder automatisiert mit Labels oder Anmerkungen versehen werden, was zeitaufwendig ist und Fachwissen erfordert.
3. Rechtliche und ethische Aspekte
Die Einhaltung von Vorschriften ist ein Muss, insbesondere beim Umgang mit sensiblen Daten:
- Datenschutz (DSGVO): Die Verarbeitung personenbezogener Daten unterliegt strengen Regeln. Es muss eine Rechtsgrundlage (z.B. Einwilligung, berechtigtes Interesse) für die Verarbeitung vorliegen.
- Zugriffsrechte: Die Zugriffskontrolle muss sicherstellen, dass nur autorisierte Personen und Systeme auf die Daten zugreifen können.
- Transparenz und Dokumentation: Insbesondere bei Hochrisiko-KI-Systemen gemäß der EU-KI-Verordnung (AI Act) sind Transparenz- und Dokumentationspflichten einzuhalten.
- Datenethik: Das Unternehmen sollte interne Richtlinien entwickeln, die den verantwortungsvollen Umgang mit Daten und den fairen Einsatz der KI regeln.
- Urheberrecht: Bei der Nutzung externer Daten oder beim Training mit öffentlich zugänglichen Inhalten sind Urheberrechte zu beachten.
Zusammenfassend lässt sich sagen, dass die Auswahl, Aufbereitung und rechtssichere Nutzung der Daten wesentliche Schritte für den erfolgreichen und verantwortungsvollen Einsatz eines firmeninternen KI-Systems sind.
SLM oder LLM
Der Hauptunterschied zwischen Small Language Models (SLM) und Large Language Models (LLM) liegt in ihrer Größe (Anzahl der Parameter), den benötigten Ressourcen und ihren Fähigkeiten.
SLM vs. LLM: Die Unterschiede
Merkmal
Small Language Model (SLM)
Large Language Model (LLM)
Parameteranzahl
Weniger Parameter (Millionen bis wenige Milliarden)
Viele Parameter (Hunderte Milliarden bis Billionen)
Training
Schnelleres Training, geringerer Energieverbrauch
Langwierig und teuer, hoher Energieverbrauch
Ressourcenbedarf
Gering
Hoch (benötigt leistungsstarke Cloud-Ressourcen)
Bereitstellung
Ideal für lokale Geräte ("Edge devices"), offline-fähig
Benötigt meist Cloud-Infrastruktur
Geschwindigkeit
Schnellere Verarbeitungs- und Reaktionszeiten
Langsamer aufgrund der Komplexität
Fähigkeiten
Spezialisiert auf spezifische, eng definierte Aufgaben; geringere Generalisierungsfähigkeit
Breites allgemeines Wissen; gut für komplexe Aufgaben und tiefes Kontextverständnis
Anpassung
Einfacher und kostengünstiger für spezifische Anwendungsfälle feinabzustimmen (Fine-Tuning)
Komplexer und teurer in der Anpassung
Zusammenfassend:
- LLMs sind Allzweckmodelle, die für ein breites Spektrum komplexer Aufgaben entwickelt wurden. Sie bieten umfassende Fähigkeiten, erfordern jedoch erhebliche Rechenressourcen.
- SLMs sind kleinere, effizientere Modelle, die für spezifische, spezialisierte Aufgaben optimiert sind. Sie sind schneller, kostengünstiger im Betrieb und können auf Geräten mit begrenzten Ressourcen (z. B. Smartphones, eingebettete Systeme) eingesetzt werden.
Die Wahl zwischen einem SLM und einem LLM hängt vom spezifischen Anwendungsfall, den verfügbaren Ressourcen und den Anforderungen an Geschwindigkeit und Datensouveränität ab.
Sicherheit für ein Firmen internes KI-System
Ein firmen internes KI-System muss extrem sicher von Hacker-Angriffen sein. Wie kann man die Sicherheit optimal realisieren?
Um ein firmeninternes KI-System optimal vor Hackerangriffen zu schützen, ist ein ganzheitlicher Sicherheitsansatz erforderlich, der sowohl allgemeine IT-Sicherheitsmaßnahmen als auch spezifische Vorkehrungen für KI-Bedrohungen umfasst. Die Sicherheit muss über den gesamten Lebenszyklus des Systems gewährleistet sein, von der Entwicklung bis zum Betrieb.
Allgemeine IT-Sicherheitsmaßnahmen
Diese grundlegenden Maßnahmen bilden die Basis für die Sicherheit des KI-Systems:
- Netzwerksegmentierung: Isolieren Sie das KI-System vom restlichen Unternehmensnetzwerk und insbesondere vom Internet, um die Angriffsfläche zu minimieren.
- Zugriffskontrollen: Implementieren Sie strikte Zugriffsbeschränkungen und das Prinzip der geringsten Rechte (Least Privilege). Verwenden Sie überall, wo möglich, eine Mehrfaktorauthentifizierung (MFA).
- Verschlüsselung: Sichern Sie sensible Daten sowohl während der Übertragung (Daten in Transit) als auch bei der Speicherung (Daten at rest) durch starke Verschlüsselung.
- Regelmäßige Updates und Patch-Management: Halten Sie die gesamte Software-Infrastruktur, einschließlich Betriebssystemen, Bibliotheken und KI-Frameworks, auf dem neuesten Stand, um bekannte Schwachstellen zu schließen.
- Mitarbeiterschulung: Sensibilisieren Sie die Mitarbeiter für Cyberbedrohungen und sichere Verhaltensweisen, da menschliches Versagen oft ein Einfallstor für Angriffe ist.
- Kontinuierliche Überwachung: Implementieren Sie Systeme zur Echtzeit-Erkennung von Anomalien und unerwartetem Verhalten im Netzwerk und innerhalb des KI-Systems.
KI-Spezifische Sicherheitsmaßnahmen
KI-Systeme bringen eigene, einzigartige Schwachstellen mit sich, die zusätzliche Schutzmaßnahmen erfordern:
- Validierung und Bereinigung von Ein- und Ausgabedaten: Filtern und validieren Sie alle Daten, die in das KI-Modell eingespeist werden, um sogenannte "Jailbreak"-Versuche oder "Injection"-Angriffe zu verhindern. Filtern Sie auch die Ausgaben, um zu verhindern, dass das System schädliche oder sensible Informationen preisgibt.
- Robustheitstests: Testen Sie das KI-Modell gezielt auf seine Widerstandsfähigkeit gegenüber manipulierten Eingabedaten (Adversarial Examples) und anderen Manipulationsversuchen.
- Menschliche Überwachung (Human-in-the-Loop): Besonders bei Hochrisiko-KI-Systemen sollte eine menschliche Aufsicht implementiert werden, um Fehlentscheidungen oder Missbrauch schnell zu erkennen und zu korrigieren.
- Erklärbarkeit der KI (Explainable AI - XAI): Machen Sie die Entscheidungen des KI-Systems nachvollziehbar, um unerwartetes oder fehlerhaftes Verhalten besser analysieren und beheben zu können.
- Sicherung der Lieferkette: Überprüfen Sie Komponenten von Drittanbietern und Open-Source-Bibliotheken, die in der KI-Infrastruktur verwendet werden, auf Sicherheitslücken.
- Datenschutz-Folgenabschätzung (DSFA): Führen Sie eine DSFA gemäß DSGVO durch, um Datenschutzrisiken, insbesondere im Umgang mit personenbezogenen Trainingsdaten, zu identifizieren und zu minimieren.
Durch die Kombination dieser technischen und organisatorischen Maßnahmen kann die Sicherheit des internen KI-Systems optimal realisiert werden. Zudem empfiehlt es sich, die Richtlinien des Bundesamts für Sicherheit in der Informationstechnik (BSI) zu konsultieren und gegebenenfalls eine Cyberversicherung abzuschließen.
_________________________________________________________________________________________________________________
ETL-Prozess
Der komplexe ETL-Prozess steht für Extrahieren, Transformieren und Laden.
Er ist die Voraussetzung für Beschaffung, Bereinigung und Strukturierung der firmeninternen Daten als Grundlage für i-KI (Firmen interne KI Lösungen). Die Grafik zeigt die Funktionweise des ETL-Prozesses:
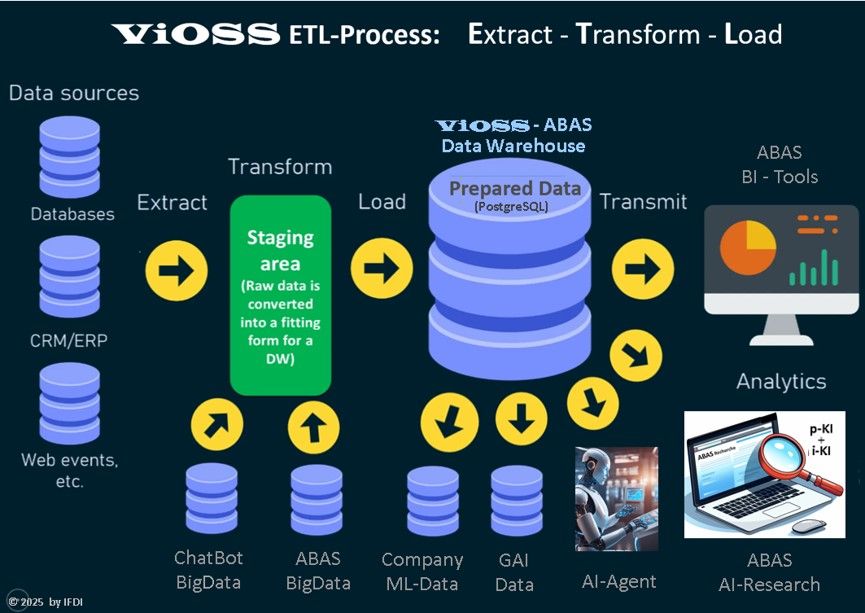
Der ETL-Prozess
Im Zusammenhang mit der Entwicklung firmeninterner KI ergeben sich für den ETL-Prozess (Extrahieren, Transformieren, Laden) folgende spezifische und erweiterte Aufgaben:
Extrahieren (Extract)
- Identifizierung und Aggregation heterogener Datenquellen: KI-Modelle benötigen oft Daten aus einer Vielzahl interner (ERP, CRM, Datenbanken, Dokumente) und potenziell externer Quellen. Die Aufgabe besteht darin, diese unterschiedlichen Datenquellen zu identifizieren und die relevanten Daten effizient zu extrahieren, unabhängig von ihrem Format (strukturiert, unstrukturiert).
- Sicherstellung der Datenherkunft und -qualität: Es muss sichergestellt werden, dass die extrahierten Daten vertrauenswürdig sind und ihren Ursprung klar nachvollziehbar ist, was für die Qualitätssicherung der späteren KI-Modelle entscheidend ist.
Transformieren (Transform)
Dies ist die kritischste Phase für die KI-Entwicklung:
- Datenbereinigung: Rohdaten enthalten oft Fehler, Inkonsistenzen oder fehlende Werte. Der ETL-Prozess muss Algorithmen zur Bereinigung implementieren, um die Genauigkeit und Konsistenz der Daten zu gewährleisten (z.B. Duplikate entfernen, Fehler korrigieren, fehlende Werte imputieren).
- Datenanreicherung (Data Enrichment): Zur Verbesserung der Vorhersagekraft der KI werden Daten angereichert, indem relevante Informationen hinzugefügt werden, etwa durch die Integration zusätzlicher interner oder externer Datensätze.
- Feature Engineering: Dies beinhaltet die Erstellung neuer, relevanter Merkmale (Features) aus den vorhandenen Daten, die für das spezifische KI- oder Machine-Learning-Modell nützlich sind. Dies erfordert oft domänenspezifisches Wissen.
- Datenformatierung und -strukturierung: Daten müssen in ein Format umgewandelt werden, das für das Training von KI-Modellen geeignet ist (z. B. Standardisierung, Normalisierung, Kodierung kategorialer Variablen).
- Daten-Annotation und -Labeling: Für viele KI-Anwendungen, insbesondere im überwachten Lernen, müssen Daten mit Labels oder Annotationen versehen werden (z.B. Bilder mit Objektnamen, Texte mit Stimmungsanalysen). Der ETL-Prozess muss die Integration dieser (oft manuellen oder teilautomatisierten) Annotationsschritte unterstützen und qualitätskontrollieren.
- Anonymisierung/Pseudonymisierung: Um Datenschutzbestimmungen (wie DSGVO) einzuhalten, müssen sensible Unternehmens- und Personendaten während der Transformation anonymisiert oder pseudonymisiert werden, bevor sie für das KI-Training verwendet werden.
Laden (Load)
- Laden in KI-spezifische Speicher: Die transformierten Daten werden nicht nur in ein klassisches Data Warehouse geladen, sondern oft in spezielle Datenplattformen wie Data Lakes oder Feature Stores, die für Machine-Learning-Workloads optimiert sind.
- Versionierung von Daten: Für die Nachvollziehbarkeit und Reproduzierbarkeit von KI-Experimenten ist es wichtig, verschiedene Versionen der Trainingsdaten zu verwalten. Der ETL-Prozess muss diese Versionierung unterstützen.
- Bereitstellung für kontinuierliches Training: Bei lernenden KI-Systemen muss der ETL-Prozess in der Lage sein, kontinuierlich neue, aufbereitete Daten für das regelmäßige Nachtrainieren der Modelle bereitzustellen.
Zusammenfassend lässt sich sagen, dass der ETL-Prozess eine zentrale Rolle in der Datenpipeline für i- KI spielt, indem er Rohdaten in hochwertige, modellierbare Datensätze umwandelt, die für den Erfolg firmeninterner KI-Projekte entscheidend sind.
_______________________________________________________________________

______________________
Technische Infrastruktur
Für eine firmeninterne (On-Premise) KI-Infrastruktur ist eine Kombination aus leistungsfähiger Hardware, spezialisierter Software und einer robusten Netzwerkarchitektur erforderlich.
Hardware-Komponenten
Die Hardware bildet das Rückgrat für das Training und den Betrieb von KI-Modellen und muss für hohe Rechenlasten ausgelegt sein.
- Prozessoren (CPUs, GPUs, TPUs):
- CPUs (Central Processing Units) sind für allgemeine Aufgaben und die Orchestrierung notwendig.
- GPUs (Graphics Processing Units) sind jedoch entscheidend, da sie für die parallele Verarbeitung von Matrix- und Vektorberechnungen, die beim KI-Training anfallen, optimiert sind.
- Spezialisiertere Hardware wie TPUs (Tensor Processing Units) oder FPGAs können je nach Anwendungsfall ebenfalls eingesetzt werden, sind aber seltener in allgemeinen On-Premise-Setups zu finden.
- Arbeitsspeicher: Es wird viel schneller Arbeitsspeicher benötigt (RAM und VRAM), oft im Bereich von 32 GB, 64 GB oder mehr, abhängig von der Komplexität der Modelle und Datenmengen.
- Speicher: Eine Kombination aus schnellem, nichtflüchtigem Speicher wie SSDs (Solid State Drives) für den schnellen Datenzugriff und größeren HDDs (Hard Disk Drives) für die Archivierung großer Datenmengen ist erforderlich.
- Netzwerk: Eine leistungsstarke Netzwerkinfrastruktur ist notwendig, um große Datensätze schnell zwischen Speicher, Recheneinheiten und den Arbeitsstationen der Entwickler zu übertragen.
Software-Stack
Die Software-Schicht ermöglicht die Entwicklung, das Training und die Bereitstellung (Deployment) der KI-Anwendungen.
- Betriebssystem und Virtualisierung: Ein stabiles Betriebssystem (oft Linux-basiert) und möglicherweise Virtualisierungs- oder Containerisierungsplattformen (z.B. Docker, Kubernetes) zur effizienten Ressourcennutzung.
- KI-Frameworks und Bibliotheken: Tools wie TensorFlow und PyTorch sind Standardbibliotheken für Machine Learning und Deep Learning.
- Programmiersprachen: Python ist die am häufigsten verwendete Sprache im KI-Bereich, oft in Verbindung mit Bibliotheken für Datenanalyse wie Pandas oder NumPy.
- Datenverarbeitungsplattformen: Für die Verarbeitung riesiger Datenmengen können verteilte Rechenplattformen wie Apache Spark nützlich sein.
- Management- und Orchestrierungstools: Software zur Verwaltung der Rechenlasten, zur Überwachung der Infrastruktur und zur Automatisierung von Arbeitsabläufen (MLOps).
Datenmanagement
KI lebt von Daten, daher ist eine robuste Datenbasis entscheidend.
- Datenpipelines: Prozesse zur Sammlung, Integration, Bereinigung und Normalisierung der Daten.
- Datenbanken und Data Lakes: Sichere Speichersysteme für große Mengen qualitativ hochwertiger Daten, die für das Training benötigt werden.
- Datensicherheit und Datenschutz: Besonders bei firmeninternen Daten sind hohe Standards für Sicherheit und Compliance erforderlich, was bei einer On-Premise-Lösung oft einfacher zu gewährleisten ist als in der Cloud.
________________________________________________________________________________________________________

KI-Hardware
Wir planen, im Bereich KI neben Beratung und Software auch zwei "Hardware-Produkte" als MSP-Partner (Managed Service Provider) im Vertrieb aufzunehmen, um unseren Kunden einen Full-Service anbieten zu können.
KI-Hardware für die KI-Software-Entwicklung
Wir werden diese neue KI-Hardware von NVDIA für unsere interne KI-Entwicklung nutzen und mit diesem Know-How dieses Produkt als MSP (Managed Service Provider) an unsere Kunden zu vertreiben.
NVIDIA Project Digits wird als AI-Supercomputer für Entwickler vermarktet. Trotz der enorm kompakten Maße verspricht das Gerät eine immense Performance, wofür Nvidia auf einen neu entwickelten GB10 "Superchip" setzt, der in Zusammenarbeit mit MediaTek entwickelt wurde.
Dieser besitzt gleich 20 Performance-Kerne, darunter zehn ARM Cortex-X925 und zehn Cortex-A725. Der integrierte Grafikchip basiert auf der Blackwell-Architektur, die man bereits von GeForce RTX 5000 kennt. Zu den Spezifikationen oder der Leistung dieser GPU macht Nvidia kaum konkrete Angaben, der Konzern verspricht lediglich 1 Petaflop Leistung (Ein PetaFLOP entspricht einer Billiarde (1015) Gleitkommaoperationen pro Sekunde), allerdings bezieht sich das auf FP4-Leistung, und ist somit nicht mit Angaben für herkömmliche Grafikkarten vergleichbar, die in der Regel die FP32-Performance nennen. Diese FP4-Leistung soll vor allem für AI-Anwendungen nützlich sein.
Ein Vorteil von Project Digits gegenüber Systemen mit dedizierten Desktop-Grafikkarten ist, dass der Grafikchip Zugriff auf mehr Speicher hat, denn Nvidia verbaut 128 GB DDR5X-Arbeitsspeicher. Mit einer 4 TB SSD, Wi-Fi, Bluetooth und USB-Anschlüssen ist Project Digits fit für den Desktop-Einsatz. Während Project Digits vor allem für Entwickler bestimmt ist, könnte dieser GB10-Chip ein erster Schritt in Richtung Desktop-Prozessoren von Nvidia sein.
Entwickler können gängige Tools wie PyTorch, Jupyter und Ollama verwenden, um Prototypen zu erstellen, Feinabstimmungen vorzunehmen und Inferenzen auf DGX Spark auszuführen und die Implementierung nahtlos in der DGX Cloud oder einem beliebigen beschleunigten Rechenzentrum oder einer beliebigen Cloud-Infrastruktur durchzuführen.
Die Vorteile: Die Unabhängigkeit der KI-Entwicklung von Rechenzentren beschleunigt die KI-Entwicklung enorm, da alle erforderlichen Tests lokal durchgeführt werden können. Und das reduziert die Kosten.
Das ist der Link zu einer ausführlichen Beschreibung.

_____________________________________________________________________________________________________________________
Hardware für die "KI-Fabrik"
Der Aufbau einer firmeninternen "KI-Fabrik" erfordert eine robuste Hardware-Infrastruktur kombiniert mit einem umfassenden Sicherheitskonzept. Hier sind die wesentlichen Hardware-Komponenten und Sicherheitsmaßnahmen:
Hardware-Komponenten für die KI-Fabrik
Die Hardware muss für rechenintensive Aufgaben wie KI-Training, Feinabstimmung (Fine-Tuning) und Inferenz (Anwendung) ausgelegt sein.
- GPUs (Graphics Processing Units): Dies ist die wichtigste Komponente, da GPUs durch parallele Verarbeitung für Deep-Learning-Aufgaben optimiert sind.
- Empfehlung: High-End-GPUs wie die NVIDIA A100, H100 oder RTX 6000 Ada-Serie werden für anspruchsvolle Workloads empfohlen. Für kleinere Installationen oder spezifische Aufgaben können auch Modelle wie die NVIDIA RTX 3080/3090 ausreichend sein.
- CPUs (Central Processing Units): Hochwertige Multi-Core-Prozessoren (z. B. Intel Xeon oder AMD EPYC) sind erforderlich, um die Gesamt-Systemleistung und Datenverarbeitung zu koordinieren.
- Arbeitsspeicher (RAM/VRAM):
- System-RAM: Mindestens 128 GB für Server-Setups, für sehr große Modelle oft 64 GB oder mehr pro Workstation.
- VRAM (Video RAM): Entscheidend für die Größe der Modelle, die geladen und trainiert werden können. GPUs mit großem VRAM (z. B. 40 GB oder mehr) sind hier von Vorteil.
- Speicher (Storage):
- NVMe-SSDs: Hohe Kapazität und Geschwindigkeit sind entscheidend für schnellen Datenzugriff und zur Vermeidung von Wartezeiten bei den Recheneinheiten. Es kann mehrere Terabyte Speicherplatz benötigen, je nach Datensatzgröße.
- Datenspeichersysteme: Skalierbare Speicherlösungen (z. B. HPE GreenLake for File Storage) zur Verwaltung massiver Datenmengen.
- Netzwerk: Hochgeschwindigkeits-Konnektivität (z. B. 400GbE oder höher) ist erforderlich, um Daten effizient zwischen den GPU-Servern und Speichersystemen zu verschieben.
- Stromversorgung und Kühlung: Leistungsstarke Hardware benötigt eine entsprechende Stromversorgung und Kühlsysteme, eventuell sogar Flüssigkühlung, um einen stabilen Betrieb zu gewährleisten.
- Racks und Gehäuse: Serverschränke mit ausreichend Platz und effizienter Luftzirkulation.
Sicherheitskonzept und -Maßnahmen (Hardware-bezogen)
Die Sicherheit der internen KI-Fabrik erfordert einen "Security-by-Design"-Ansatz, der die gesamte Infrastruktur und den Lebenszyklus der KI berücksichtigt.
- Physische Sicherheit: Beschränken Sie den physischen Zugang zu den Servern und Racks auf autorisiertes Personal.
- Netzwerksegmentierung: Isolieren Sie die KI-Infrastruktur vom restlichen Unternehmensnetzwerk mit dedizierten Hardware-Firewalls (Next-Generation Firewalls) und sicheren VPN-Verbindungen.
- Hardware Security Modules (HSMs): Verwenden Sie HSMs, um kryptografische Schlüssel für die Daten- und Modellverschlüsselung sicher zu speichern und zu verwalten. Dies schützt vor unbefugtem Zugriff auf sensible Daten und gestohlene Modelle.
- Hardware-basierte Sicherheitsfunktionen: Nutzen Sie Plattformen, die integrierte Hardware-Sicherheitsfunktionen bieten (z. B. Intel vPro oder spezifische Sicherheitschips), um Angriffsflächen zu reduzieren.
- Verschlüsselung: Implementieren Sie eine durchgängige Verschlüsselung ruhender Daten (data at rest, z. B. auf SSDs) und übertragener Daten (data in transit).
- Zugriffskontrollen (Identity and Access Management, IAM): Setzen Sie strikte, rollenbasierte Zugriffskontrollen (RBAC) und das Prinzip der geringsten Privilegien (Least Privilege) auf Hardware- und Softwareebene durch, um sicherzustellen, dass nur autorisierte Benutzer auf bestimmte Ressourcen zugreifen können.
- Überwachung und Auditing: Implementieren Sie kontinuierliche Überwachungssysteme, um ungewöhnliches Verhalten oder potenzielle Sicherheitsbedrohungen in Echtzeit zu erkennen und Audit-Protokolle zu führen.
- Supply Chain Security: Stellen Sie sicher, dass die Hardware von vertrauenswürdigen Anbietern bezogen wird und der gesamte Lebenszyklus der Komponenten nachvollziehbar ist, um Manipulationen auszuschließen
In diesem Zusammenhang werden wir mit dem Lieferanten HPE kooperieren.
HPE ist die Abkürzung für Hewlett Packard Enterprise Company, ein großes US-amerikanisches Informationstechnikunternehmen. Es ist aus der Aufspaltung der ursprünglichen Hewlett-Packard Company im Jahr 2015 hervorgegangen.
Geschäftsfelder von Hewlett Packard Enterprise (HPE)
HPE konzentriert sich auf Lösungen und Dienstleistungen für Geschäftskunden und Großunternehmen in den Bereichen:
- Server, Storage und Networking: Bereitstellung von Hardware und Lösungen für Rechenzentren, Datenspeicherung (z. B. HPE Alletra, HPE MSA Storage) und Netzwerkinfrastrukturen (über die Tochtergesellschaft Aruba Networks).
- High Performance Computing & KI: Entwicklung von Supercomputern (nach der Übernahme von Cray) und KI-Anwendungen für intensive Berechnungen und Datenanalysen.
- Hybrid Cloud & Edge-to-Cloud: Bereitstellung von Cloud-nativen Dateninfrastrukturlösungen, die eine nahtlose Verwaltung von Daten und Workloads über lokale Rechenzentren (On-Premise), Edge-Standorte und Public Clouds hinweg ermöglichen, unter anderem über die Plattform HPE GreenLake.
HPE (Hewlett Packard Enterprise) und NVIDIA pflegen eine intensive strategische Partnerschaft, die sich hauptsächlich auf die Entwicklung und Bereitstellung von Lösungen für Künstliche Intelligenz (KI) und Supercomputing konzentriert.
Die Zusammenarbeit umfasst folgende Kernbereiche:
- KI-Computing-Lösungen ("NVIDIA AI Computing by HPE"):
HPE und NVIDIA haben gemeinsam integrierte, vorkonfigurierte Lösungen entwickelt, die darauf abzielen, die Einführung von KI in Unternehmen zu beschleunigen. Dazu gehört die "HPE Private Cloud AI", die auf validierten Designs von NVIDIA basiert und es Unternehmen erleichtert, generative KI-Anwendungen in ihrer eigenen, kontrollierten privaten Cloud-Infrastruktur zu betreiben.
- Hardware-Integration: Die Partnerschaft beinhaltet die Integration von NVIDIAs leistungsstarken GPUs (wie den Blackwell- und RTX PRO 6000 Server Edition GPUs) und KI-Software in HPE-Systeme, insbesondere in die HPE ProLiant Compute Server und HPE Cray Supercomputing-Systeme.
- Supercomputer-Projekte: Ein prominentes Beispiel für die Zusammenarbeit im Bereich Supercomputing ist der geplante Bau eines neuen Supercomputers im Leibniz-Rechenzentrum (LRZ) in Deutschland ("Blue Lion").
- Vereinheitlichte Datenschicht: Ein Fokus der Entwicklung liegt auch auf einer einheitlichen Datenschicht, die Unternehmensdaten für KI-Anwendungen nutzbar und zugänglich machen soll.
- Vereinfachte Implementierung: Ziel ist es, die Komplexität der KI-Implementierung zu reduzieren, sodass Unternehmen KI-Modelle schneller (teilweise wird eine Bereitstellung in wenigen Sekunden und mit wenigen Klicks angestrebt) und einfacher nutzen können.
Zusammenfassend lässt sich sagen, dass die Partnerschaft darauf abzielt, die Expertise von HPE im Enterprise-Bereich mit NVIDIAs führender KI-Technologie zu bündeln, um die industrielle Revolution der generativen KI voranzutreiben
Eine firmeninterne (On-Premise) KI-Lösung bezeichnet die Implementierung und den Betrieb von KI-Systemen auf der eigenen Hardware und Infrastruktur eines Unternehmens, anstatt cloudbasierte Dienste zu nutzen. Dies bietet spezifische Vorteile hinsichtlich Datenschutz, Sicherheit und Kontrolle über sensible Unternehmensdaten.
Folgen Sie diesem
Link.

______________________________________________________________________________________________________________
Software-Module der i-KI
im operativen Betrieb

Chat Bots für die Telefonzentrale:
Carl und Carla
Wie sieht die optimale Struktur für einen Chat Bot am Telefon aus?
Die optimale Struktur für einen Chatbot, der als Telefonzentrale dient, kombiniert eine klare Dialogführung mit intelligenter Verarbeitung und effizienter Weiterleitung. Der Fokus liegt auf einer nutzerzentrierten, modularen Architektur, die sowohl einfache, vordefinierte Anfragen als auch komplexere, dynamische Gespräche abwickeln kann.
Kernkomponenten der Struktur
Die Architektur eines solchen Systems besteht typischerweise aus mehreren Bausteinen:
- Spracherkennung (ASR) & Text-zu-Sprache (TTS): Wandelt die gesprochene Sprache des Anrufers in Text um und umgekehrt, um eine natürliche Konversation zu ermöglichen.
- Natural Language Processing (NLP) & Understanding (NLU): Analysiert den Text, um die Absicht (Intent) des Anrufers und relevante Informationen (Entities) zu identifizieren (z. B. "Ich möchte mit der Buchhaltung sprechen", Intent: Abteilungsanfrage, Entity: Buchhaltung).
- Dialog-Management-Engine: Dies ist das Herzstück, das den Gesprächsverlauf steuert. Es bestimmt, wie der Bot auf die Absichten reagiert, ob er weitere Informationen benötigt und wann er das Gespräch beenden oder übergeben muss.
- Wissensdatenbank: Eine strukturierte Sammlung von FAQs, Prozessanleitungen und Unternehmensdaten, auf die der Bot zugreifen kann, um Fragen direkt zu beantworten (oft unter Nutzung von Retrieval Augmented Generation - RAG).
- Integrationsschicht: Schnittstellen zu internen Systemen wie CRM, Ticket-Systemen oder Kalendern, um Aktionen auszuführen (z. B. einen Termin buchen, ein Ticket erstellen).
- Übergabemechanismus (Handover): Definiert den nahtlosen Übergang zu einem menschlichen Mitarbeiter, falls der Bot nicht mehr weiterhelfen kann.
Optimaler Gesprächsablauf (Flow)
Der Dialogfluss sollte benutzerfreundlich und effizient gestaltet sein:
- Begrüßung und Identifizierung: Der Bot meldet sich mit einer klaren Ansage, stellt sich vor (z. B. "Hallo, ich bin Ihr virtueller Assistent") und fragt nach dem Anliegen des Anrufers.
- Absichtserkennung: Der Bot analysiert die Antwort, um das Ziel des Anrufers zu bestimmen.
- Einfache Anfragen: Wenn die Absicht klar ist und in der Wissensdatenbank abgedeckt, liefert der Bot die Antwort oder führt die Aktion aus (z. B. "Unsere Öffnungszeiten sind...").
- Komplexe/unklare Anfragen: Wenn die Absicht unklar ist, stellt der Bot präzisierende Fragen, um das Anliegen einzugrenzen
3. Abfrage relevanter Informationen: Bei Bedarf (z. B. für eine Weiterleitung) fragt der Bot nach spezifischen
Daten wie Namen, Kundennummer oder Abteilung.
4. Aktion/Weiterleitung:
- Kann das Problem gelöst werden, wird die Lösung präsentiert.
- Ist eine menschliche Interaktion nötig, leitet der Bot an die zuständige Person oder Abteilung weiter und übergibt idealerweise die bisher gesammelten Informationen an den Mitarbeiter.
5. Abschluss und Feedback: Der Bot beendet das Gespräch und bittet eventuell um eine kurze Bewertung.
Best Practices
- Realistische Erwartungen: Der Bot sollte nur wenige Dinge sehr gut können, anstatt viele Dinge schlecht.
- Klare Kommunikation: Machen Sie dem Anrufer klar, dass er mit einem automatisierten System spricht.
- Natürliche Sprache: Verwenden Sie eine klare und natürliche Ausdrucksweise.
- Fehlerbehandlung: Planen Sie Fallback-Nachrichten für den Fall, dass der Bot etwas nicht versteht oder eine Anfrage nicht bearbeiten kann, und bieten Sie immer die Option zur Weiterleitung an einen Menschen an.
- Kontinuierliches Training: Überwachen Sie die Bot-Leistung und trainieren Sie das System regelmäßig mit neuen Daten und Anfragen, um die Qualität zu verbessern
____________________________________________________________________________________________________________

KI-Agenten
Die optimale Struktur für "Agentic AI" in Unternehmen zeichnet sich durch ein mehrschichtiges, modulares Design und eine enge Verzahnung mit bestehenden Geschäftsprozessen und menschlicher Aufsicht aus. Anstatt eine isolierte IT-Funktion zu sein, muss sie in die gesamte Unternehmensökosystem integriert werden.
Kernkomponenten der optimalen Struktur
Architektonische Integration (Mehrschichtiges Design):
- Unternehmensökosystem-Ebene: Die operative Oberfläche, auf der die KI-Agenten mit bestehenden ERP-Systemen, Legacy-Plattformen und anderen IT-Tools interagieren.
- Marktplatz für KI-Ebene: Eine zentrale Plattform, die die verschiedenen KI-Agenten und -Dienste verwaltet und orchestriert.
- Daten- und Governance-Ebene: Eine robuste Grundlage für hochwertige Daten, Sicherheitsmaßnahmen und Compliance-Protokolle, die für alle Agenten zugänglich sind.
Organisatorische Anpassung:
- Zentrale Koordination und dezentrale Ausführung: Ein zentrales "KI-Kompetenzzentrum" (AI Center of Excellence) kann Governance, Best Practices und Technologie-Assessments standardisieren, während die Implementierung und der Betrieb der Agenten in den jeweiligen Fachabteilungen (z.B. HR, Vertrieb, Lieferkette) erfolgen.
- Interdisziplinäre Teams: Teams sollten nicht nur aus KI-Experten, sondern auch aus Fachexperten der jeweiligen Geschäftsbereiche bestehen, um sicherzustellen, dass die Agenten reale Probleme lösen und in bestehende Arbeitsabläufe eingebettet sind.
- Definition von Rollen und Verantwortlichkeiten: Klare Zuweisung von Verantwortlichkeiten für die Entwicklung, Überwachung, Fehlerbehebung und Wartung der KI-Agenten.
Prozessuale Einbettung:
- Mensch-in-der-Schleife (Human-in-the-Loop, HITL): Systeme müssen von Anfang an menschliche Eingriffspunkte (Escalation Paths) beinhalten, insbesondere bei komplexen oder kritischen Entscheidungen. Ein progressives Vertrauensmodell kann dabei helfen, die menschliche Aufsicht schrittweise zu reduzieren, sobald Agenten ihre Zuverlässigkeit unter Beweis gestellt haben.
- Klare Zieldefinition: Implementierung beginnt mit der Identifizierung spezifischer, hochvolumiger oder komplexer Anwendungsfälle mit klaren Geschäftszielen, anstatt KI um der KI willen einzusetzen.
- Iterative Entwicklung: Start mit Pilotprojekten und kontinuierliche Verbesserung basierend auf Feedback und Leistungskennzahlen.
Technologische Best Practices:
- Modulare und verteilte Architektur: Verwendung modularer Softwarearchitektur, um Skalierbarkeit und Anpassungsfähigkeit zu fördern und die Kommunikation zwischen verschiedenen Multi-Agenten-Systemen zu erleichtern.
- Standardisierte Schnittstellen: Definition strikter Formate für Dateninputs und -outputs, um Fehler durch nicht übereinstimmende Strukturen zu minimieren.
Zusammenfassend lässt sich sagen, dass die optimale Struktur eine hybride Organisation ist, in der autonome KI-Agenten als digitale Mitarbeiter nahtlos neben menschlichen Teams arbeiten, gesteuert durch eine zentrale Governance und unterstützt durch eine robuste, integrierte technologische Architektur.
____________________________________________________________________________________________________________________________

KI gestützte Workflow Automatisierung
Die optimale Struktur für eine KI-gestützte Workflow-Automatisierung integriert KI-Fähigkeiten nahtlos in die traditionellen Phasen der Prozessautomatisierung, um nicht nur Regeln abzuarbeiten, sondern auch zu lernen, sich anzupassen und intelligentere Entscheidungen zu treffen.
Die Struktur lässt sich in folgende Kernkomponenten und Phasen unterteilen:
1. Prozessdefinition und Datenvorbereitung
Der Grundstein jeder Automatisierung liegt in einem klaren Verständnis des zu automatisierenden Prozesses.
- Prozessanalyse: Identifizieren Sie wiederkehrende, regelbasierte Aufgaben, die sich für eine Automatisierung eignen, oder komplexere Aufgaben, die von intelligenten Entscheidungen profitieren.
- Datensammlung: Stellen Sie sicher, dass ausreichend relevante Daten vorhanden sind, da KI-Modelle aus diesen lernen. Eine solide Datenbasis ist entscheidend für die Genauigkeit der KI.
- Datenaufbereitung: Die gesammelten Daten müssen bereinigt, beschriftet und vorverarbeitet werden, um sie für das KI-Modell nutzbar zu machen. Dies ist oft der zeitaufwändigste Schritt.
2. KI-Integration und Workflow-Design
In dieser Phase wird die Intelligenz in den Workflow eingebettet.
- Modellauswahl und -training: Wählen Sie das passende KI-Modell (z.B. maschinelles Lernen, Large Language Models) basierend auf der Aufgabe aus und trainieren Sie es mit den vorbereiteten Daten.
- Architektur: Verbinden Sie das KI-Modell über APIs oder dedizierte Plattformen mit den bestehenden Systemen (wie CRM oder ERP) und dem Workflow-Management-Tool.
- Regelwerk und Logik: Definieren Sie, wann die KI eingreifen soll, welche Aufgaben sie übernimmt und wann menschliches Eingreifen erforderlich ist. KI-Agenten können hierbei Routineaufgaben übernehmen.
3. Ausführung und Orchestrierung
Der Workflow wird in Betrieb genommen, wobei die KI die Steuerung oder Teilaufgaben übernimmt.
- Trigger-Definition: Legen Sie die Auslöser fest, die den automatisierten Prozess starten.
- Aufgabenverteilung: Das System führt die definierten Schritte aus, delegiert Aufgaben an die KI (z.B. Datenanalyse, Content-Generierung) und leitet das Ergebnis an den nächsten Schritt oder einen menschlichen Mitarbeiter weiter.
- Plattform: Eine zentrale Workflow-Automatisierungsplattform orchestriert den gesamten Prozess und sorgt für einen reibungslosen Ablauf über verschiedene Tools hinweg.
4. Überwachung, Evaluierung und kontinuierliche Verbesserung
Ein entscheidendes Merkmal von KI-gestützten Workflows ist ihre Fähigkeit zur Anpassung und Optimierung.
- Echtzeit-Monitoring: Überwachen Sie den Workflow kontinuierlich, um Fehler, Engpässe oder Schwachstellen frühzeitig zu erkennen.
- Leistungsevaluierung: Analysieren Sie die Ergebnisse der KI-gesteuerten Schritte, um sicherzustellen, dass sie die gewünschten Geschäftsziele erreichen.
- Feedbackschleifen: Implementieren Sie Mechanismen, durch die das KI-Modell aus den Ergebnissen lernt und sich kontinuierlich verbessert, um flexibler und effizienter zu werden.
Zusammenfassend lässt sich sagen, dass eine optimale Struktur einen klaren Rahmen schafft, der menschliche Expertise mit der lernenden und anpassungsfähigen Natur der KI verbindet, um Insellösungen zu vermeiden und Transparenz zu gewährleisten.
________________________________________________________________________________________________________

Firmen interne KI-Recherchen
Eine strukturierte Vorgehensweise für firmeninterne KI-Recherchen umfasst typischerweise die folgenden Phasen und Elemente
1. Initialisierung und Problemdefinition
- Bedarfsanalyse: Identifizieren, welche spezifischen Geschäftsprobleme oder Ineffizienzen durch KI gelöst werden sollen (z.B. verbesserter Kundensupport, Prozessautomatisierung, Datenanalyse).
- Projektziele festlegen: Klare, messbare Ziele definieren, die mit der Unternehmensstrategie übereinstimmen.
- Projektverantwortlichkeit bestimmen: Festlegen, wer das Projekt leitet und welche Abteilungen (IT, Fachabteilungen, Management) involviert sind.
- Budget und Ressourcen: Sicherstellen, dass notwendige finanzielle Mittel, Personal und Infrastruktur bereitstehen.
2. Datenerhebung und -aufbereitung
- Datenquellen identifizieren: Bestimmen, welche internen Daten (SharePoint, Wikis, Ticketsysteme, PDFs, E-Mails, etc.) für die KI benötigt werden.
- Datenqualität sicherstellen: Die Daten müssen von hoher Qualität sein, um genaue Vorhersagen und Ergebnisse zu gewährleisten. Dies beinhaltet Bereinigung, Strukturierung und Validierung.
- Datenschutz und Compliance: Sicherstellen, dass alle Datenschutzrichtlinien (wie DSGVO) und internen Richtlinien eingehalten werden.
3. Technologische Infrastruktur und Modellwahl
- Technologie-Stack: Auswahl der geeigneten Plattformen (Cloud-Dienste wie Azure, AWS, Google Cloud oder On-Premise-Lösungen).
- Modell-Auswahl: Entscheidung zwischen der Nutzung interner Modelle, öffentlicher Modelle oder einer Kombination (Make-or-Buy-Entscheidung).
- Architektur: Aufbau der Systemarchitektur, oft unter Verwendung von Ansätzen wie Retrieval Augmented Generation (RAG) für interne Wissensdatenbanken.
4. Entwicklung und Implementierung
- Entwicklung: Training, Anpassung und Integration der KI-Lösung in bestehende Systeme (z.B. CRM, BI-Tools).
- Prototyping: Start mit einem Proof of Concept oder Pilotprojekt, um die Machbarkeit und den Nutzen zu testen.
- Skalierbarkeit: Sicherstellen, dass die Lösung bei Erfolg auf das gesamte Unternehmen ausgeweitet werden kann.
5. Evaluation und Betrieb
- Testing Framework: Implementierung von Testverfahren, um die Qualität und Genauigkeit der KI-Ergebnisse kontinuierlich zu überwachen und Probleme wie "Halluzinationen" zu minimieren.
- Monitoring und Optimierung: Laufende Überwachung der Systemleistung, Kosten und Sicherheitsereignisse (Observability).
- Schulung und Akzeptanz: Schulung der Mitarbeiter im Umgang mit den neuen KI-Tools, um die Akzeptanz zu fördern und den Nutzen zu maximieren.
- Feedback-Schleifen: Etablierung von Prozessen zur Sammlung von Nutzerfeedback für kontinuierliche Verbesserungen.
Governance und Kultur
Parallel zu diesen Phasen ist eine übergreifende Governance-Struktur wichtig, die Rollen, Regeln und Verantwortlichkeiten für den ethischen und sicheren Einsatz von KI festlegt.
___________________________________________________________________________________________________________
Kombination interner KI-Recherchen mit externen,
generativen KI-Systemen (z.B. Chat-GPT, Google-KI, ...)
Die Kombination interner KI-Recherchen mit generativen KI-Systemen erfolgt meist über die Integration der generativen KI in eine bestehende Enterprise-Search-Lösung oder durch die Nutzung von Techniken wie Retrieval-Augmented Generation (RAG).
Die effektivste und sicherste Methode ist RAG. Dabei wird das generative KI-Modell nicht direkt mit den internen Daten trainiert, sondern es greift während der Beantwortung einer Anfrage auf die Unternehmensdatenbanken zu.
Der Prozess funktioniert typischerweise in folgenden Schritten:
- Indexierung: Interne Dokumente und Daten werden gesammelt, aufbereitet und in einer durchsuchbaren Datenbank (oft eine Vektordatenbank) indexiert.
- Abfrage: Ein Benutzer stellt eine Frage an das System.
- Informationsextraktion (Retrieval): Das System durchsucht die internen Datenbanken nach relevanten Informationen, die zur Beantwortung der Frage nützlich sind.
- Generierung: Die relevanten Informationen werden zusammen mit der ursprünglichen Frage an das generative KI-Modell (wie GPT-4 oder ähnliche) übergeben. Das Modell nutzt diese Informationen als Kontext, um eine präzise, auf den internen Daten basierende Antwort zu formulieren.
- Ausgabe: Der Benutzer erhält eine kohärente und genaue Antwort, oft mit Verweisen auf die internen Quelldokumente.
Vorteile dieser Kombination
- Genauigkeit und Relevanz: Die Antworten der KI basieren auf den aktuellsten und spezifischen internen Unternehmensdaten, wodurch "Halluzinationen" (falsche Informationen) des Modells minimiert werden.
- Datensicherheit und Compliance: Sensible interne Daten verlassen die sichere Unternehmensumgebung nicht, da das Modell nur Zugriff auf die extrahierten, relevanten Textpassagen erhält. Dies hilft bei der Einhaltung von Datenschutzbestimmungen wie der DSGVO.
- Effizienz: Mitarbeiter können schnell auf Unternehmenswissen zugreifen, ohne lange in verschiedenen Systemen suchen zu müssen, was die Produktivität steigert.
- Wissensmanagement: Unternehmensinternes Wissen wird besser nutzbar und zugänglich gemacht, auch bei Fluktuation von Mitarbeitern.
Schritte zur Implementierung
- Bedarfsanalyse: Klären Sie, welche spezifischen internen Recherchen die KI unterstützen soll.
- Datenaufbereitung: Stellen Sie sicher, dass Ihre internen Daten gut strukturiert, zugänglich und von ausreichender Qualität sind.
- Technologieauswahl: Wählen Sie eine geeignete Enterprise-Search-Lösung oder RAG-Plattform, die sich mit dem gewünschten generativen KI-Modell verbinden lässt.
- Integration und Tests: Integrieren Sie die Systeme und testen Sie die Funktionalität und Sicherheit gründlich.
- Schulung und Richtlinien: Schulen Sie Ihre Mitarbeiter im sicheren und effektiven Umgang mit dem neuen System und stellen Sie klare interne Richtlinien auf, insbesondere bezüglich sensibler Daten